![]()
ISSN 2379-5980 (online) DOI 10.5195/LEDGER.2024.377
RESEARCH ARTICLE
Dissecting the NFT Market: Implications of Creation Methods on Trading Behavior
Pegah Beikzadeh,* Maedeh Mosharraf †
Abstract. Amidst the frenzy surrounding Non-Fungible Tokens (NFTs) in 2021, the concept of digital assets and trading was redefined. Although the initial hype may have subsided, NFTs continue to drive innovation in ownership, with substantial revenue streams flowing through the market. This transformative shift underscores the importance of discerning the factors that shape this ecosystem. This paper delves into the intricate dynamics of the NFT market, particularly focusing on the impact of creation methods—whether hand-drawn or artificial intelligence (AI)-generated—on market behavior. In a comprehensive analysis of the NFT market, we have analyzed a vast dataset comprising 1,478,556 transactions of NFT art from the OpenSea marketplace in 2023 to explore correlations and patterns between key transactional features. Furthermore, we employed regression models to predict the sales of an NFT and classification models to distinguish between hand-drawn and AI-generated NFTs. Finally, by comparing different machine learning models, we identified the most appropriate model for analyzing the market, considering the non-linear relationships and complex nature of the NFT market. Overall, the results provided in this research can lead to making more informed decisions regarding investment, creation, and trading.
![]()
∗ P. Beikzadeh (p.beikzadeh@sbu.ac.ir) is a Bachelor’s student of Computer Engineering at Shahid Beheshti University, Tehran, Iran.
† M. Mosharraf (m_mosharraf@sbu.ac.ir) is an Assistant Professor of Computer Science and Engineering at Shahid Beheshti University, Tehran, Iran.
![]()
The surge of Non-Fungible Tokens (NFTs) has transformed the digital landscape and reshaped our perception of ownership. Although the market may not be as feverish as it was in 2021, the revenue continues to grow.1 Projections indicate that NFT market revenue is set to reach USD 2.378 billion in 2024, boasting an annual growth rate of 9.1%.2 With the increasing transaction volume of this domain, it is crucial to elucidate its patterns and correlations in order for stakeholders to make informed decisions and capitalize on market opportunities.
The NFT market is primarily composed of a dynamic community of buyers and sellers, with digital artists making up a significant proportion. This ecosystem thrives on creativity as artists leverage blockchain technology to tokenize their digital creations, turning them into unique and verifiable assets for sale. Simultaneously, machine learning algorithms and Artificial Intelligence (AI) tools have introduced innovative abilities for creating digital art using automation.3 By utilizing AI algorithms, such as Generative Adversarial Networks (GANs), digital artists can unlock new dimensions of ingenuity and harness computer algorithms to create and modify digital creations.4 Amidst this revolution, generative art has been ushered into a new era with the emergence of NFTs. Generative art involves using an autonomous system to create digital art. In an algorithmic process, one-of-a-kind artworks are generated autonomously. Subsequently, digital artists willing to present their art in the NFT market attach the AI-generated art to an NFT. In contrast to AI-generated NFTs, certain artists meticulously craft every aspect of their digital creation and use traditional methods to create their artwork by hand. NFTs created by this group of artists are referred to as hand-drawn NFTs.5 There are contradicting opinions on how to place value on AI-generated art compared to hand-drawn art. To further investigate how each group is perceived, we analyzed multiple studies centered around this topic. It is concluded that people tend to show more interest in hand-drawn art and when the presence of human touch is mentioned in the information provided by an art piece, it is more likely that it will be rated higher.6,7 Therefore, higher value should be associated with hand-drawn art and the source of creation should be specified to the audience for each piece of digital art.8,9 An opposing perspective suggests that machine algorithms and AI may serve as powerful tools designed to assist artists,10 and while art experts show less liking to AI-generated art, non-experts show no preference at all.11
In this study, we aim to analyze the creation method of NFT art and how it impacts other key features such as sales volume and pricing.
The primary questions addressed in this research are as follows:
Q1: Is there a discernible contrast in perceived value between hand-drawn and AI-generated NFTs?
Q2: Do buyers consider the creation method of an NFT significant, or is their primary focus solely on the end product?
Q3: What correlations and patterns exist between different factors of the NFT Market?
In addition to answering these questions, the results obtained from this study can provide a foundation for future research and broader development in the field of blockchain and cryptocurrency studies, as the growth of the NFT market creates a need to understand its dynamics.
The rest of the paper is structured as follows: first, in the section dedicated to related work, we provide an overview of studies conducted in the field of NFTs, highlighting their contributions and insights. Next, in Section 3, we discuss the methodology used for data collection and analysis. We then present the results of our study in Section 4. Finally, in the concluding section, we summarize key findings and suggest potential paths for future research endeavors.
Numerous studies have been conducted to analyze the NFT market. Nadini et al. (2021) illustrates statistical features and changes in the market, clustering NFTs based on their visual features.12 Subsequently, the probability of a second sale is predicted along with the NFT’s price. The research in Costa et al. (2023) focuses on predicting the price of an NFT by considering its visual and textual features.13 Cho et al. (2023) examines visual features, sale patterns, and price changes of a limited collection of highly-valued NFTs.14
Tang et al. (2023) charts the growth of the NFT market, emphasizing the ongoing potential of digital assets. A machine learning model is then implemented to assess the importance of transactional features on market fluctuations.15 Vasan et al. (2022) highlights the crucial role of the market in shaping the network of art pieces, demonstrating that the average price of different artworks created by a single artist tends to remain consistent.16 The study further emphasizes that artists often receive repeated investment from a small group of investors, underscoring the vital importance of artist-collector ties. Similar to the findings in Nadini et al. (2021), Alizadeh et al. (2023) concludes that a small number of users are responsible for the majority of sales.17 Another finding suggests that the fluctuations of the NFT market are directly influenced by the price of Ethereum. Further investigations concluded that trends and buyers’ preferences can be identified by analyzing NFTs purchased in the same time period. Ante (2021) views NFTs not as a currency but as an asset. Additionally, the relationship between the NFT market and cryptocurrencies is explored, with results indicating that changes in the Bitcoin and Ethereum markets affect the NFT market, while there is no reverse effect.18 Ghosh et al. (2023) conducts predictive analytics on NFTs and DeFi assets during the COVID-19 pandemic, emphasizing on the black box nature of time series models and utilizing Explainable AI (XAI) to gain further insights on model predictions.19 Wang et al. (2023) explores a similar topic, aiming to predict NFT price fluctuations. 20 It is concluded that the historical average price and creators’ information are key factors in predicting NFT prices.
Table 1 provides a summary of research conducted on the NFT market.
Table 1. Details of related work.
| Reference | Data | Aim | Model | Key Result |
| Nadini et al. (2021)12 | 6.1M transactions (2017-2021) | Discovering the relationship between visual features of an NFT and its price | Convolutional neural networks and regression | NFT prices can be predicted with more than 80% accuracy based on visual features. |
| Vasan et al. (2022)16 | 48,000 NFTs (2021) | Categorizing buyers and sellers in the NFT market | Clustering algorithms | The number of new participants in the NFT market influences the overall number of NFT sales. |
| Alizadeh et al. (2023)17 | 77M transactions (2017-2022) | Exploring the relationship between buyers and sellers in the NFT market | Graph and network algorithms | There are multiple hidden networks of buyers and sellers in the NFT market. |
| Ante (2021)18 | 6.1M Transactions (2021) | NFT price prediction based on visual and textual features | Neural networks | NFT prices can be predicted with more than 70% accuracy based on visual and textual features. |
| Costa et al. (2023)13 | 81M Transactions (2017-2022) | Finding key factors influencing the NFT market | Regression models | The average daily price of NFTs has the greatest impact on market fluctuations. |
| Tang et al. (2023)15 | 1231 daily observations on the volume of NFT sales (2018-2021) | Discovering the relationship between cryptocurrencies and the NFT market | Regression models | Changes in Bitcoin and Ethereum markets influence the NFT market. |
| Cho et al. (2023)14 | 8 popular collections (2021-2022) | Analyzing NFT prices, sale patterns, and visual features | Graph and network algorithms | The rarity of an NFT influences its price. |
| Ghosh et al. (2023)19 | Daily closing prices of the top four coins in the NFT and DeFi market (2020-2022) | Predicting NFT and DeFi prices | Time series models | The daily price of NFTs and DeFi is influenced by past movements. |
| Wang et al. (2023)20 | 15,000 NFTs (2023) | Predicting NFT prices based on provided information | AdaBoost and Random Forest | Price history and relative account information can be used to predict NFT prices. |
To the best of our knowledge, while the impact of NFT visual features has been explored, there is a notable gap in research concerning the generation of NFT art and its market implications. As generative AI and innovative methods for creating NFTs are expanding, understanding their influence on market dynamics becomes increasingly vital. The present research strives to recognize the role of creation methods, alongside other market factors, to bridge these existing gaps in the literature.
The aim of this study is to analyze trading behaviors and uncover correlations in the NFT market, focusing specifically on how the method of creating NFT art—whether it is hand-drawn or AI-generated—affects market dynamics. The analysis presented in this research is theoretical. However, by conducting operational research, we can investigate the answers to the primary questions mentioned in this study. By providing a data-driven perspective we hope to contribute valuable insights to the existing body of knowledge, not only considering transactional trends but also by examining the impact of an NFT’s origin on market outcomes and the shaping of digital assets.
3.1 Data Collection—As explained in Section 2, prior studies explored the long-term dynamics of the NFT market. However, these analyses have primarily relied on data predating 2022. To this end, this study focuses on transactions that occurred in 2023 (from January through December). For this purpose, the collected data must be a suitable representation of the NFT market, ensuring that the results are broadly applicable and generalizable. After evaluating multiple NFT trading platforms, the OpenSea marketplace was selected. With a transactional volume exceeding $20 billion and a supply of more than 80M NFTs, OpenSea is recognized as the first and largest NFT market.21 We utilized an open-source tool called the OpenSea API, which provides an interface for fetching NFT metadata and transactional information.22
3.2 Data Preparation—Eventually, a dataset of 1,478,556 transactions was collected. Subsequently, we focused on data cleaning by removing irrelevant features such as non-numeric data including names, hash addresses, and links. Following the data cleaning, numerical features were normalized to bring all variables into a comparable range, improving the performance of subsequent analyses. Additionally, categorical variables were encoded using one-hot encoding. The processed dataset was then subjected to feature scaling to further normalize the data, ensuring that the results are both robust and reliable.
Based on the primary questions posed in the introduction, it was necessary to add a “generator” feature to indicate whether the NFT is AI-generated or hand-drawn. Given that the dataset provided by OpenSea, while comprehensive, lacks explicit information about the method of creation, we have employed a pragmatic approach to address this gap. We analyzed the description field of each traded NFT, identifying keywords such as “generative”, “generated”, “generator”, “algorithm”, and “random” as indicators of an algorithmic process in creating the NFT. Therefore, NFTs containing at least one of these keywords in their description were labeled as AI-generated.
This methodology is the most feasible given the constraints of the dataset. The primary rationale for this approach is the lack of direct metadata regarding the creation method of the NFTs. By utilizing keyword-based classification, we have sought to approximate the intended categorization as closely as possible with the available data.
It is important to acknowledge that due to the limitations in the dataset metadata and the recorded features in the NFT market, this process may categorize some hand-made NFTs and some AI-generated NFTs in the same category, potentially affecting the accuracy of subsequent processing steps. As a result, this limitation impacts the evaluation of the two first questions outlined in the introduction, while the assessment of buyer behavior relies on the description provided by the NFT creator. In other words, if the price, number of sales, or other characteristics are influenced by how it has been created, the buyer must have been informed of the creation method through the NFT description.
Moreover, the accuracy of the classification can be significantly improved by incorporating computer vision techniques. For instance, Convolutional Neural Networks (CNNs) can be employed to identify patterns, textures and styles that distinguish between different creation methods. Generative Adversarial Networks (GANs) can further enhance this process by generating synthetic images and comparing them to the dataset to assess the likelihood of AI involvement in NFT creation. Furthermore, engaging a large pool of human annotators to classify the artworks based on visual inspection or additional contextual information could enhance accuracy. This method would involve substantial time and cost for annotation, and managing consistency across multiple reviewers presents its own challenges. Analyzing specific features such as color patterns, brush strokes, and other stylistic elements could also be used to develop a more nuanced classification system. This approach would require expertise in art analysis and complex feature extraction techniques.
These methods introduce complexity and resource requirements beyond the scope of our current research. Our chosen keyword-based methodology, though decent, represents a practical solution given the dataset constraints and allows us to proceed with meaningful analysis of the transactional features associated with AI-generated versus human-drawn NFTs.
Finally, the dataset of NFT transactions used in this research includes various features, categorized as numeric, binary, and additional attributes. The numeric features include:
Number of sales: The number of times the NFT was sold before the transaction in question.
Total supply: The number of NFTs in the collection to which the traded NFT belongs.
NFT USD price: The USD price of the NFT.
NFT crypto price: The cryptocurrency price of the NFT.
Crypto to ETH price: The value of the cryptocurrency used to purchase the NFT, converted into Ethereum.
Crypto to USD price: The value of the cryptocurrency used to purchase the NFT, converted into US dollars.
Creator fee: The fee charged by the creator.
Seller fee: The fee charged by the seller.
Table 2 provides a summary of the numeric features of the dataset.
Table 2. Numeric transactional features of the dataset.
Feature | Unit | Mean | Median |
Number of sales | Count | 267 | 2 |
Total supply | Count | 212,416 | 0 |
NFT USD price | USD | 706.919 | 22.075 |
NFT crypto price | Cryptoa | 4.14 | 0.45 |
Crypto to ETH price | ETH | 0.7 | 1.0 |
Crypto to USD price | USD | 1,530.27 | 2,153.58 |
Creator fee | USD | 6,763,836 | 500 |
Seller fee | USD | 6,764,086 | 750 |
a In this row, each NFT is displayed with the cryptocurrency used for the transaction, such as Bitcoin or Ethereum. To use this feature, the equivalent value of the exchanged cryptocurrency is calculated in Ethereum and USD, and these values are listed in the following two rows of the table.
Additional features of each NFT required for processing the transactions are listed below:
Contract owner ID: The unique ID of the transaction contract owner.
Transaction month: The month in which the transaction took place. The binary features of this dataset are:
Contract type: Non-fungible or semi-fungible.
Is ETH: Whether the NFT was purchased with Ethereum or not.
Safe-listed status: Verified or non-verified collection.
Has rarity: Whether the NFT includes a rarity value in its information.
Has creator fee: Whether the creator profits from this transaction or not.
Generator: AI-generated or hand-drawn.
3.3 Data Analysis—In order to answer the primary questions outlined in this study, we intended to employ datamining and machine learning techniques, specifically regression and classification. Machine learning algorithms encompass a range of computational methods that enable systems to learn patterns and relationships from data without being explicitly programmed.23 Regression algorithms are used to predict continuous outcomes based on input variables, while classification techniques assign categorical labels to instances based on their features. In the context of analyzing the NFT market, by predicting important transactional features such as NFT sales using regression models, we are able to analyze how various factors, including the creation method of the NFT, influence the target variable. Furthermore, applying classification techniques with the NFT “generator” as the target label enables us to differentiate between NFTs created by humans and those generated by algorithms. This binary classification aids in understanding how creation methods affect NFT characteristics, helping us discern patterns and optimize strategies within the market.
These models provide a clear and interpretable framework for understanding the static relationship between variables, aligning with the primary objectives of our study, which is to identify and quantify the impact of creation methods on NFT market characteristics. This is why they are also used in various related studies on the NFT market, some of which are mentioned above.
Other machine learning models such as Deep Learning and Ensemble methods, while powerful and potentially more accurate, often operate as black boxes, making it difficult to interpret the results and understand the underlying factors driving predictions. Studies that have utilized these more complex models, such as Ghosh et al. (2023),19 have noted this limitation and some have incorporated interpretable machine learning techniques to mitigate the problem.24
Moreover, time-dependent analyses such as price fluctuations and cryptocurrency values through time are influenced by market sentiment, trends, and external economic conditions. Given the broad range of variables and the temporal dependencies involved, time series forecasting would be more appropriate for such investigations. Given the added complexity of these models, the simplicity, transparency, and interpretability of regression and classification make them the most suitable choices for answering the specific questions posed in this research, enabling us to draw meaningful insights into the factors that drive the NFT market.
To ensure the reliability and accuracy of our models, we employed several model validation techniques, including k-fold cross-validation to assess the model’s performance on unseen data and avoid overfitting. Additionally, we split our dataset into training and testing subsets to ensure that our models generalize well to new data. These evaluation techniques are crucial for confirming that the models are robust, reliable, and capable of providing meaningful insights into the factors influencing the NFT market.
3.4 Model Evaluation—The performance of each model was measured using metrics such as R-Squared, Mean Absolute Error, and Accuracy, which provided insights into how well our models captured the variability in NFT transactions.
4.1 General Market Analysis—By calculating the average cost of NFTs in these two groups, we find that AI-generated NFTs are priced higher than hand-drawn NFTs. Data processing shows that, on average, AI-generated tokens are priced 25.02% higher than tokens that do not mention being AI-generated in their descriptions. Furthermore, the median price of AI- generated NFTs is 3.16 times higher than that of tokens that are not AI-generated based on their description. Therefore, most AI-generated NFTs are priced higher compared to hand-drawn NFTs.
Figure 1 visually represents the interquartile range of both groups, highlighting the central 50% of the price distribution. The line inside denotes the mean value. The average price of AI- generated and hand-drawn NFTs is $856.61 and $685.13 respectively, while the median in these two groups is $63.26 and $20.06 respectively. These values suggest that a small number of NFTs have exceptionally high prices, which significantly raise the average price, whereas the majority of NFTs have lower prices clustered around the median.
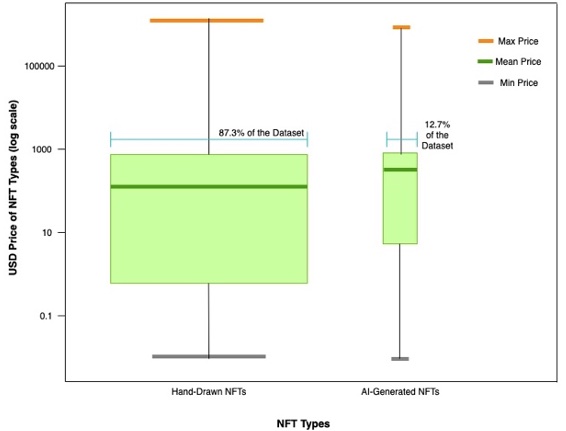
Fig. 1. Range of AI-generated and hand-drawn NFTs prices.
Evaluating the correlation matrix reveals a very weak but positive correlation between NFT prices and the NFT generator. Figure 2 illustrates the correlation among all transactional features in our dataset.
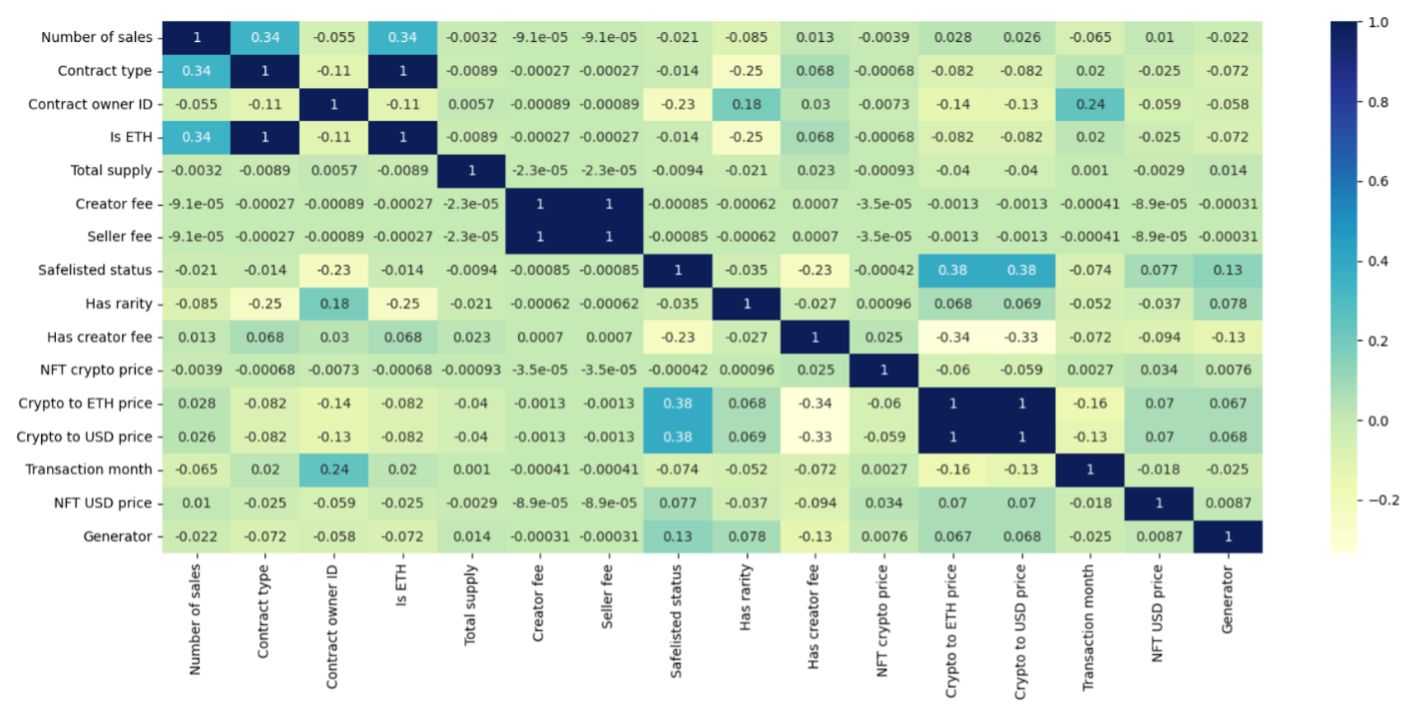
Fig. 2. Correlation matrix of transactional features.
Since the value of this feature is assigned as 1 for AI-generated tokens, we can infer that NFTs indicating the presence of AI in their generator have slightly higher prices than the remaining NFTs. However, the number of sales for each NFT correlates weakly yet negatively with the generator. This suggests that NFTs in the “hand-drawn” category achieve more sales. In other words, while AI-generated NFTs command higher prices, they have fewer sales, whereas hand-drawn NFTs are priced lower but are traded more frequently. Nonetheless, because these correlations are very weak and only reflect linear associations rather than direct effects, the results should be interpreted with caution.
It is also worthwhile to discuss the correlation between transactional features and the price of an NFT. The correlation between the number of sales and the price of a token is very weak, yet suggests a potential trend where higher prices might be associated with more sales. Additionally, there is a slight positive correlation between an NFT being safe-listed and its price. Safe-listing may imply a higher level of trust or legitimacy, which could enhance its perceived value. The weak negative correlation between the enforcement of a creator fee and the price indicates that buyers might be less inclined to pay higher prices if a portion is allocated to the creator as fee. Finally, the positive correlation between the generator of an NFT and its price indicates that AI-generated NFTs tend to have higher prices.
4.2 Random Forest Regressor Results—To predict the number of NFT sales based on other transactional features, several regression models were employed. Each regression model has its own assumptions and biases, so using a variety of models helps reduce the risk of model bias or overfitting and provides a more comprehensive exploration of the data. Comparing the performance of these models can be done using metrics such as R-squared, mean-squared error, and others. This allows for the selection of the most suitable model for prediction and inference. Analysis of the dataset with different regression models reveals that the Random Forest Regressor yields the highest R-squared value. Table 3 summarizes the results.
Table 3. Random forest regressor results.
Metric name | Metric value | Metric description |
R-squared (R2) | 0.9937 | Reflects the model’s ability to predict the majority of the variability in the data. |
Mean Absolute Error (MAE) | 9.9276 | The average magnitude of errors in predictions without considering the direction. |
Root Mean Squared Error (RMSE) | 184.6134 | The standard deviation of the residuals. |
Root Mean Squared Logarithmic Error (RMSLE) | 0.4839 | The logarithm of the ratio between predicted and actual values. |
Mean Absolute Percentage Error (MAPE) | 1.3487 | The average absolute error as a percentage of the actual values. |
Upon examining the data from Table 3, we observe an R2 value of 0.9937. This indicates that approximately 99.37% of the variability in NFT sales can be explained by other transactional features in the regression model. The MAE of 9.9276 shows that, on average, the difference between the predicted and actual number of sales of each NFT is approximately 9 units. The RMSE is 184.6134, which relatively high. This metric is sensitive to outliers. Therefore, we can sense the presence of outliers in our dataset, contributing to prediction errors. The RMSLE is 0.4839, indicating a moderate average error in the ratio of predicted to actual values. Finally, the MAPE is very high with a value of 1.3487, reflecting significant error between the predicted and actual values.
The results presented in Table 3 are derived from the data in Table 4, which reflects the outcomes obtained from applying regression models to our dataset.
Table 4. Regression model results.
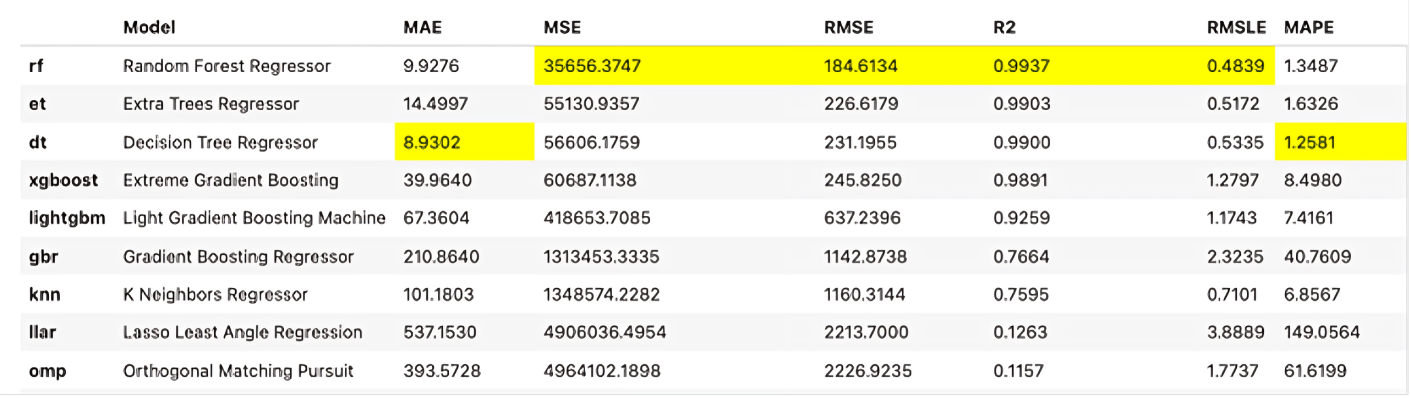
To enhance the performance of the regression model, particularly in terms of metrics such as RMSE, RMSLE, and MAPE, it is crucial to identify and address outliers. We proceeded to scrutinize the data and identify instances where the deviation between the predicted and actual values exceeded 50%.
Our analysis reveals that approximately 26.59% of the test dataset surpasses the predetermined error threshold, contributing to the high MAPE. The instances of this subset cannot be unequivocally labeled as outliers. However, they possess certain distinguishing attributes that differentiate them from the majority of the dataset. Features such as association with a prominent owner or creator, unique artistic styles, and limited editions may justify their classification as outliers.
>Upon comparing this subset with the remainder of the test dataset, we notice that the average price in the first group is $1223, nearly double that of the second group, which averages $619. Furthermore, when comparing the average number of sales, the disparity becomes even more pronounced. The first group averages 10 sales, whereas the second group averages 407. This contrast implies that the data points in the first group likely consist of rare NFTs with higher prices and fewer sales, whereas the second group likely includes more commonly sold items with lower values. By analyzing these transactional patterns, stakeholders can determine which group an NFT belongs to and adjust their investment strategies accordingly. For example, rare and valuable NFTs may benefit from targeted marketing strategies and retention by collectors, whereas more commonly traded NFTs could be better suited to volume-based trading.
By excluding this subset from the remainder of our test dataset, the regression model yields improved results. Table 5 showcases the updated values.
Table 5. Improved random forest regressor results.
Metric name | Metric value |
R2 | 0.9991 |
MAE | 4.7238 |
RMSE | 87.1420 |
RMSLE | 0.1816 |
MAPE | 0.1614 |
Table 5 shows that, in addition to a slightly improved R2, the MAE has decreased by 5 units. The RMSE has also fallen to 87.1420, indicating a reduction in outliers within the dataset. The RMSLE has improved to 0.1816, nearly one third of its previous value. Finally, the MAPE has seen the most significant decrease, dropping to 0.16, which represents a 16% error between the predicted and actual values. This suggests that the model has become more accurate and reliable. We conducted a comprehensive analysis on the importance of transactional features in predicting NFT sales. The following list illustrates the hierarchy of features, ranked from most to least significant, derived from Figure 3:
Contract owner: The contract owner is highly significant, as sellers with strong followings can influence the demand for their NFTs.
Price: The NFT price is a key factor affecting purchasing decisions. High-value NFTs may attract high demand and sales, while lower-priced NFTs may be more accessible to a larger number of buyers, potentially increasing sales.
Crypto to USD price: This feature slightly influences NFT sales, indicating that the value of the cryptocurrency used to purchase the NFT plays a role in sales. NFTs traded with certain cryptocurrencies may appeal to a broader audience.
Contract type: The type of token, whether non-fungible or semi-fungible, affects its uniqueness and scarcity, which are critical factors in influencing demand and, consequently, sales.
Transaction month: The month in which an NFT is purchased impacts its sales. Seasonal trends and market sentiments can affect buyer behavior, with higher interest rates in certain months.
Safelist status: an NFTs approval status influences its sales. Being safe listed can enhance perceived legitimacy and credibility, making it more appealing to buyers.
Generator: While this feature has a minor role in predicting sales, the correlation indicates that awareness of an NFT’s origin can influence its demand.
Creator fee: The creator fee affects buyers’ perceptions of an NFT’s value. Higher fees may deter price-sensitive buyers, while reasonable fees can attract more buyers by signaling a fair distribution of profits to the creator while still offering competitive pricing.
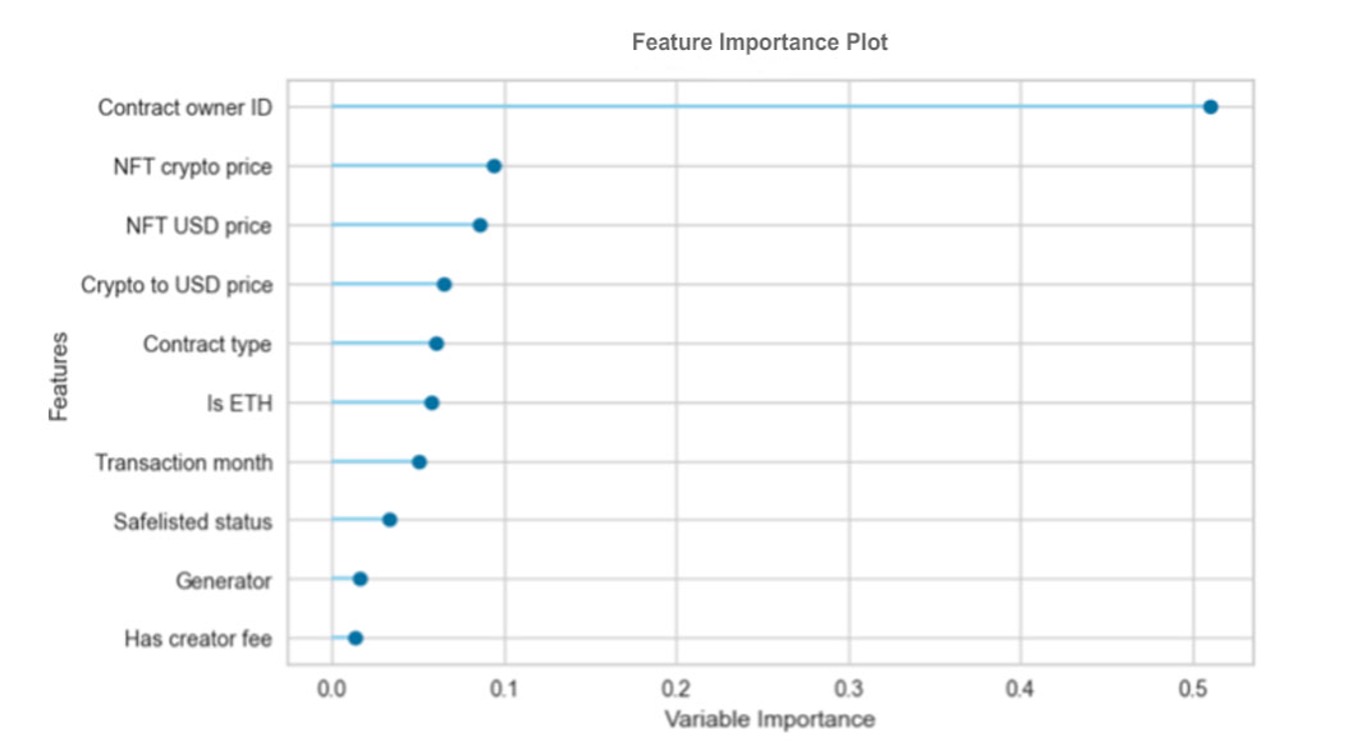
Fig. 3. Random forest regressor feature importance.
Overall, the results presented in Table 3, along with the high R2 Score for the Random Forest Regressor model, demonstrate that this model is well-suited for our data. Additional parameters such as RMSE indicate that there is room for improvement, particularly in reducing prediction errors and in handling outliers more effectively. Given the nature of NFT sales, where extreme values can occur frequently, it is crucial to focus on refining the model’s approach to managing outliers to enhance accuracy.
4.3 Random Forest Classifier Results—As shown in Table 6, implementing Random Forest Classifier to predict NFT categories based on their creation method yields promising results in terms of accuracy and precision. In this classification, class 1 and class 0 represent AI-generated and hand-drawn NFTs, respectively.
Table 6. Random forest classifier results.
Measure name | Measure value | Measure description |
Accuracy | 0.9785 | The rate of correct classifications. |
Area Under the ROC Curve (AUC) | 0.9976 | The area under the Receiver Operating Characteristic (ROC) curve which plots the true positive rate against the false positive rate. |
Recall | 0.9782 | The true positive rate. |
Precision | 0.9789 | The proportion of predicted positive instances that were correctly classified. |
|
F1 Score |
0.9785 |
The harmonic mean of precision and recall. |
|
Cohen’s Kappa |
0.9570 |
The level of agreement between actual and predicted values. |
|
Matthews Correlation Coefficient (MCC) |
0.9570 |
The quality of binary classifications. |
By analyzing the values from Table 6, we observe an accuracy of 0.9785 for the classification model. This demonstrates that the model can correctly predict the generator for 97.85% of NFTs based on their transactional features. The AUC is notably high at 0.9976, demonstrating the model’s excellent discrimination ability to discriminate between the two classes. The recall value of 0.9782 indicates that the model correctly classifies 97.82% of AI- generated NFTs. A precision of 0.9789 shows that 97.89% of NFTs classified as AI-generated art were in fact generated by AI. The F1 Score, also at 0.9785, reflects that the model’s strong performance in achieving both high precision and recall. Cohen’s Kappa is also significantly high at 0.9570, indicating a strong agreement between the model’s predictions and actual classifications, beyond what would be expected by chance. The MCC, also rated at 0.9570, further confirms the mode’s efficiency in accurately predicting both classes.
The information in Table 6 is derived from implementing different classification algorithms, as shown in Table 7.
Table 7. Classification results.
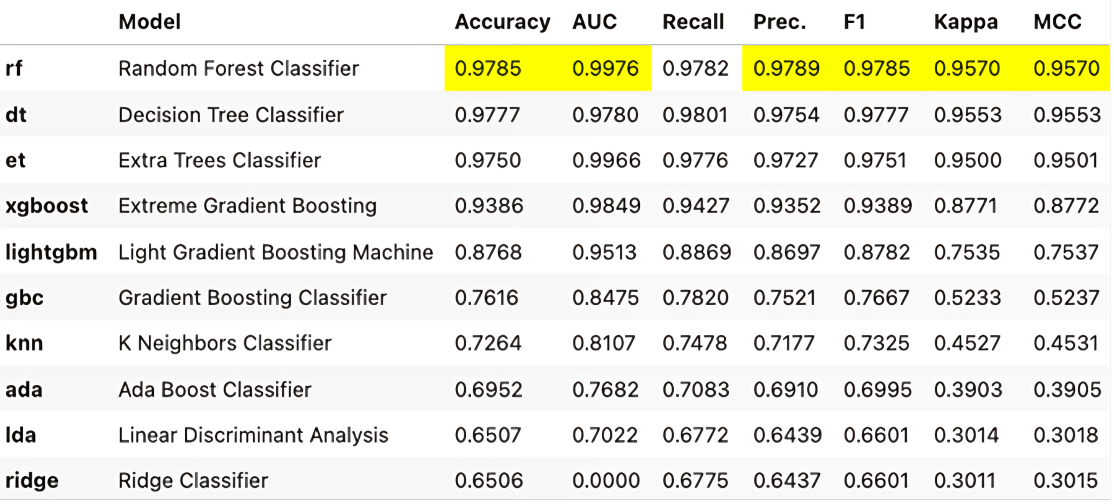
Figure 4 illustrates the importance of transactional features in classifying tokens as either AI-generated or hand-drawn NFTs. The features, ranked from most to least significant, are as follows:
Contract owner: The seller plays a huge role in classifying NFTs based on their generator. This may be because many sellers specialize in trading specific collections with similar traits, including how the NFT was created. NFT creators may also exhibit specific patterns or algorithms.
Total supply: This feature indirectly aids the model by indicating the availability and rarity of the NFT.
Price: The price of the NFT influences the model’s accuracy in categorizing NFTs, suggesting different market values for each class.
Token ETH and USD price: The type and value of the cryptocurrency used in NFT transactions impact the model’s behavior, indicating distinctive market dynamics and trading patterns for each NFT class.
Seller and creator fee: Different groups of NFTs, based on their creation method, may have varying pricing strategies and fee enforcement mechanisms, leading to values that influence their classification.
Transaction month: The time of purchase captures temporal patterns and changes in demand for each group, highlighting how trends affect the popularity of AI-generated and hand-drawn NFTs.
Number of sales: The frequency of sales indicates demand and popularity, with different patterns emerging for AI-generated versus hand-drawn NFTs, aiding their classification.
Has rarity: Whether a rarity percentage is mentioned influences how rare the NFT is perceived, with different levels of importance depending on the group.
Safelist status: This feature reflects approval mechanisms that may vary between groups based on platform policies.
NFT standard and contract type: These features demonstrate that the standard used for the NFT and its fungibility differ between classes based on their creation purposes.
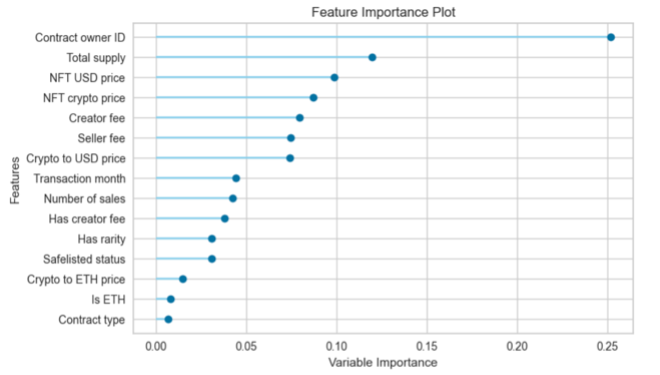
Fig. 4. Random forest classifier feature importance.
Figure 5 represents the confusion matrix of the Random Forest Classifier. The model was applied to a randomly sampled, balanced dataset where the number of instances in each class is relatively equal. The results indicate that the model performs slightly better in classifying hand- drawn NFTs. Out of 43,350 hand-drawn NFTs and 48,635 AI-generated NFTs in the test dataset, 42,738 and 47,809 instances were correctly classified, respectively, resulting in an accuracy of approximately 98.6% for hand-drawn NFTs compared to 98.3% for AI-generated NFTs.
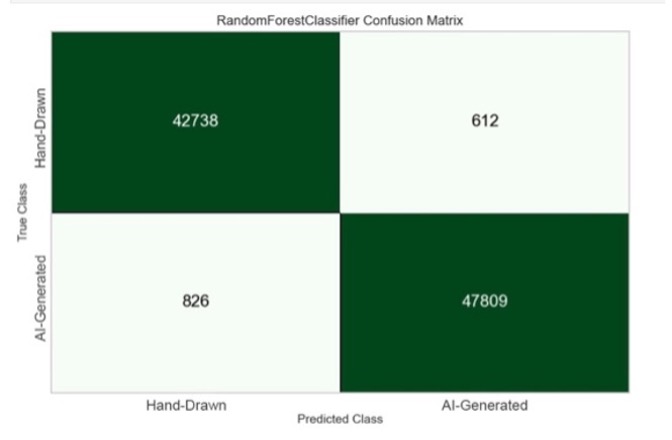
Fig. 5. Random forest classifier confusion matrix.
The Cumulative Gains Curve plotted in Figure 6 offers further insights into the classification model’s performance. This curve visually represents the proportion of correctly classified instances as the cumulative percentage of the dataset examined increases. It shows that the model performs better in identifying hand-drawn NFTs compared to AI-generated ones.
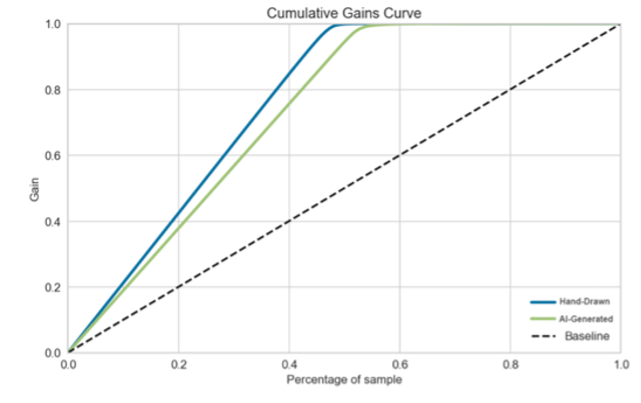
Fig. 6. Random forest classifier cumulative gains curve.
4.4 Comparing Different Models—By studying Table 4 and Table 6 representing results from different models of regression and classification respectively, we can conclude that regression trees and classification trees deliver the best performance. These achieve a higher R2 Score and precision compared to Gradient Boosting and K-Nearest Neighbors regression and classification models. This superior performance can be attributed to several factors discussed below:
Non-linearity: Regression Trees and Classification Trees, particularly Random Forest models can capture non-linear relationships between features and target variables. In contrast, other models converge to the optimal solution much slower despite recognizing a few non-linear correlations. The NFT marketplace is characterized by complex, non-linear patterns, where meaningful inferences require considering multiple factors and combining certain features. Therefore, Regression Trees and Classification Trees can produce more desirable outcomes when analyzing the NFT market.
Complexity and flexibility: Tree models, such as Regression Trees and Classification Trees are inherently more complex than Gradient Boosting and K-Nearest Neighbor models, making them less prone to overfitting. Additionally, they ignore inconvenient features and select the most valuable ones when expanding the tree and splitting nodes. Since features may not be adequately filtered before training a data analysis model, Gradient Boosting and K-Nearest Neighbor Models may not perform as well. Impactful features and determinative factors are not specified in the complex ecosystem of the NFT market and we can only obtain information about the effect of each variable after executing our machine learning models. As a result, Regression Trees and Classification Trees can help us evaluate variable importance and reach desired outcomes without specifying convenient features.
Handling outliers: Regression Trees and Classification Trees partition the feature space and make predictions based on the majority class or the target variable average. As a result, abnormal data does not impact the model as opposed to Gradient Boosting and K-Nearest Neighbor models, which rely on distance metrics and sequential fitting. The NFT market is very prone to having numerous abnormalities and unexpected outcomes including a wide range of prices and other transactional features, making models with outlier-handling strategies a better fit.
It is important to note that the choice of algorithm ultimately depends on the specific characteristics of the dataset and necessary trade-offs between model complexity, interpretability and performance.
This study has provided valuable insights into the transactional correlations in the NFT market, particularly highlighting the impact of creation methods on market behavior. The findings indicate that AI-generated NFTs typically command higher prices, while hand-drawn NFTs achieve more sales, likely due to their perceived authenticity and human touch. Machine learning techniques, especially Random Forest models, proved effective in predicting sales and classifying NFTs based on their creation method with high accuracy. It is important to mention that the unpredictable nature of the NFT market underscores the margin of error inherent in machine learning analyses, as evidenced by correlation values and regression metrics. While the method of NFT art generation may modestly influence transaction patterns, it serves as a valuable tool in uncovering latent patterns and relationships within the NFT market when observed alongside other essential features.
We encountered several limitations during data collection that impacted the accuracy of our analysis. A major constraint was the anonymity of data owners, which prevented us from extracting specific characteristics or behaviors from individual participants in the NFT market. Furthermore, the method of NFT creation was not directly indicated in the dataset. To overcome this limitation, techniques such as image processing, crowdsourced annotations, and feature engineering can be particularly useful in analyzing visual features of NFTs to infer whether they are AI-generated or hand-drawn. Future research could benefit from exploring these advanced methodologies to refine the classification process and provide deeper insights into the market dynamics of NFT art.
Finally, integrating more advanced methodologies such as time series models in future analyses could offer significant benefits. Regression and classification models do not account for temporal dynamics. NFTs, like many financial assets, experience fluctuations over time that are not captured by static models. Models such as ARIMA (Auto Regressive Integrated Moving Average) and LSTM (Long Short-Term Memory) networks can help in forecasting prices and sales by analyzing temporal patterns and trends. These models would enable us to track fluctuations over specific periods, offering a more comprehensive view of the NFT market dynamics and enhancing the predictive capabilities regarding price movements and transaction volumes.
MM proposed the idea and supervised the project. PB developed the model, performed simulations, and drafted the manuscript. Both authors approved the final version.
The author declares that they have no known conflicts of interest as per the journal’s Conflict of Interest Policy.
1 S. R. Angelov, “Granger-Causal Effects of Consumer Behavior on NFT Sales,” Legder 9 16-29 (2024) https://doi.org/10.5195/ledger.2024.312.
2 No Author. “NFT – Worldwide,” Statista (accessed 27 January 2024) https://www.statista.com/outlook/fmo/digital-assets/nft/worldwide.
3 Wang, T. “A Deep Learning-Based Programming and Creation Algorithm of NFT Artwork,” Mobile Information Systems 2022.2325179 1-10 (1 September 2022) https://doi.org/10.1155/2022/2325179.
4 Radermecker, A.-S. V., Ginsburgh, V. “Questioning the NFT ‘Revolution’ Within the Art Ecosystem,” Arts 12.1 25 (30 January 2023) https://doi.org/10.3390/arts12010025.
5 Shahriar, S., Hayawi, K. “NFTGAN: Non-Fungible Token Art Generation Using Generative Adversarial Networks,” in ICMLT '22: Proceedings of the 2022 7th International Conference on Machine Learning Technologies 255-259 (2022) https://doi.org/10.1145/3529399.3529439.
6 Ragot, M., Martin, N., Cojean, S. “AI-generated vs. Human Artworks. A Perception Bias Towards Artificial Intelligence?,” in CHI EA '20: Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing System 1-10 (2020) https://doi.org/10.1145/3334480.3382892.
7 Bellaiche, L. et al. “Humans Versus AI: Whether and Why We Prefer Human-Created Compared to AI- Created Artwork,” Cognitive Research: Principles and Implications 8 42 (4 July 2023) https://doi.org/10.1186/s41235-023-00499-6.
8 Blaine Horton Jr, C., White, M. W., Iyengar, S. S. “Bias Against AI Art Can Enhance Perceptions of Human Creativity,” Scientific Reports 13 19001 (3 November 2023) https://doi.org/10.1038/s41598-023-45202-3.
9 Messingschlager, T. V., Appel, M. “Mind Ascribed to AI and the Appreciation of AI-Generated Art,” New Media & Society (26 September 2023) https://doi.org/10.1177/14614448231200248.
10 Amanbay, M. “The Ethics of AI-Generated Art,” SSRN (accessed 12 September 2023) https://ssrn.com/abstract=4551467.
11 Gu, L., Li, Y. “Who Made the Paintings: Artists or Artificial Intelligence? The Effects of Identity on Liking and Purchase Intention,” Sec. Personality and Social Psychology 13 941163 (5 August 2022) https://doi.org/10.3389/fpsyg.2022.941163.
12 Nadini, M. et al. “Mapping the NFT Revolution: Market Trends, Trade Networks, and Visual Features,” Scientific Reports 11 20902 (22 October 2021) https://doi.org/10.1038/s41598-021-00053-8.
13 Costa, D., La Cava, L., Tagarelli, A. “Show Me Your NFT and I Tell You How It Will Perform: Multimodal Representation Learning for NFT Selling Price Prediction,” in WWW '23: Proceedings of the ACM Web Conference 2023 1875-1885 (2023) https://doi.org/10.1145/3543507.3583520.
14 Cho, J. B., Serneels, S., Matteson, D. S. “Non-Fungible Token Transactions: Data and Challenges,” Data Science in Science 2.1 2151950 (9 February 2023) https://doi.org/10.1080/26941899.2022.2151950.
15 Tang, M., Feng, X., Chen, W. “Exploring the NFT Market on Ethereum: A Comprehensive Analysis and Daily Volume Forecasting,” Connection Science 35.1 2286912 (14 December 2023) https://doi.org/10.1080/09540091.2023.2286912.
16 Vasan, K., Janosov, M., Barabasi, A. “Quantifying NFT-Driven Networks in Crypto Art,” Scientific Reports 12 2769 (17 February 2022) https://doi.org/10.1038/s41598-022-05146-6.
17 Alizadeh, S., Setayesh, A., Mohamadpour, A., Bahrak, B. “A Network Analysis of the Non-Fungible Token (NFT) Market: Structural Characteristics, Evolution, and Interactions,” Applied Network Science, 8 38 (26 June 2023) https://doi.org/10.1007/s41109-023-00565-4.
18 Ante, L. “The Non-Fungible Token (NFT) Market and Its Relationship with Bitcoin and Ethereum,” FinTech 1.3 216-224 (6 June 2021) https://doi.org/10.3390/fintech1030017.
19 Ghosh, I., Alfaro-Cortes, E., Gamez, M., Garcia-Rubio, N. “Prediction and Interpretation of Daily NFT and DeFi Prices Dynamics: Inspection Through Ensemble Machine Learning & XAI,” International Review of Financial Analysis 87 102558 (2023) https://doi.org/10.1016/j.irfa.2023.102558.
20 Wang, Z., Chen, Q., Lee, S.-J. “Prediction of NFT Sale Price Fluctuations on OpenSea Using Machine Learning Approaches,” Computers, Materials & Continua 75.2 2443-2459 (2023) https://doi.org/10.32604/cmc.2023.037553.
21 No Author. “About,” OpenSea (accesed 17 January 2024) https://opensea.io/about.
22 No Author. “OpenSea API Overview,” OpenSea (accessed 17 January 2024) https://docs.opensea.io/reference/api-overview.
23 Sarker, I. H. “Machine Learning: Algorithms, Real‐World Applications and Research Directions,” SN Computer Science 2 160 (22 March 2021) https://doi.org/10.1007/s42979-021-00592-x.
24 Du, M., Liu, N., Hu, X. “Techniques for Interpretable Machine Learning.” Communications of the ACM 63.1 68-77 (2020) https://doi.org/10.1145/3359786.
